目录
请求数据
分类: crawlerTTyb 2017-05-18 584
前面学习的爬虫知识都是将页面的数据抓取下来,专业来说也就是 get 数据,而有时候在 get 的同时,还会向后台发送请求数据。
在百度搜索的时候,打开百度搜索的主页 https://www.baidu.com/ ,这一过程是 get 的行为;如果在搜索栏中输入某一个关键字,并点击了 百度一下 ,这时候前端会将你的关键词发送到后端中处理,也就是从数据库中提取出与关键词相关的东西,将其展现在页面。这里也是 get 的行为,但是在 get 之前却将关键字发送给了后端。
那么在爬虫中,怎样写代码才能像浏览器一样,向后台请求需要的信息呢?
涉及到 请求数据 的时候,需要经常查看网页给后台请求了那些数据,建议大家使用 firefox 浏览器,对浏览器增加一个新的插件 firebug 。这是一个很好的查看网页源码以及各种网页信息的插件:
安装完毕后,打开 firefox 浏览器,进入百度搜索,然后按下 F12 :
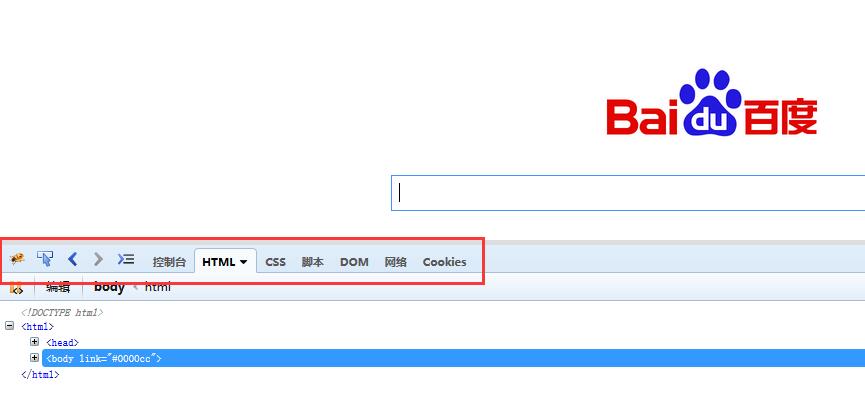
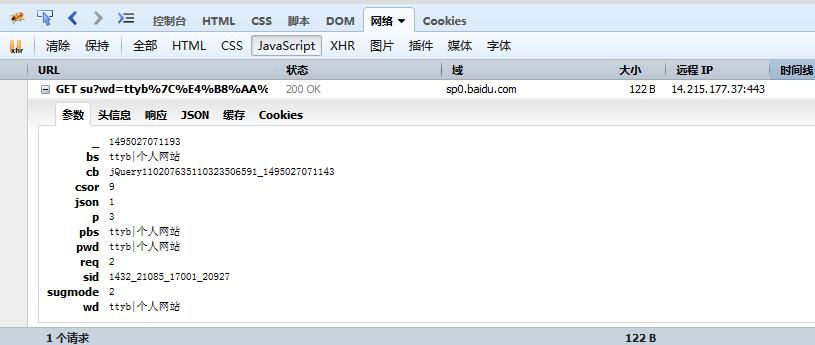
点击 网络 -> JavaScrip ,在输入关键词之前清除 历史记录 和 清空请求列表,然后在百度搜索栏中输入关键字 TTyb|个人网站 ,那么网络下面会出现如下情况:
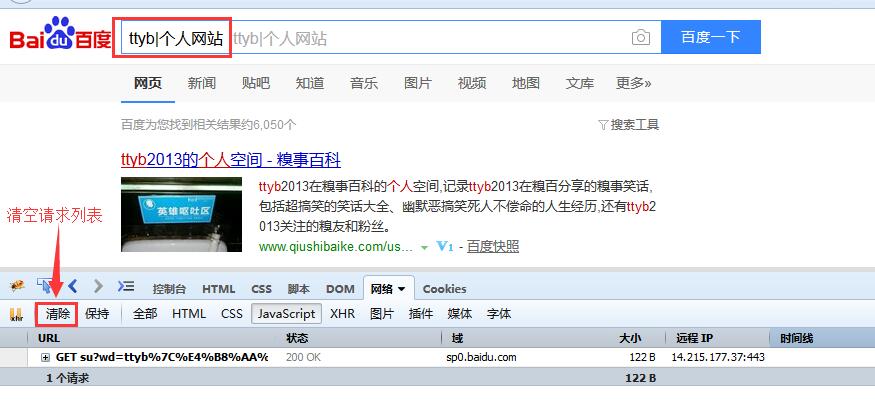
点击 url 前面的 + 号,点击到 参数 的位置,可以看到当输入关键词的时候,百度向后台请求了这些数据:
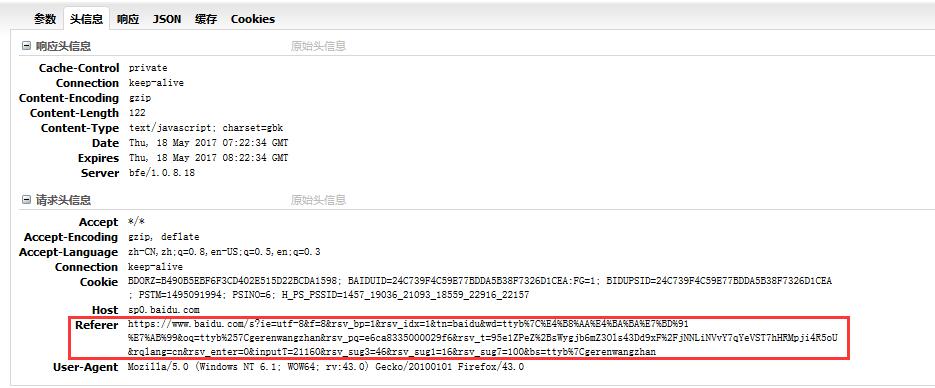
而点开 头信息 -> 请求头信息 -> Referer ,可以看到网址的构造结构为:
https://www.baidu.com/s? + 请求参数的字段
那么,只要按照上面的网址结构构造 url ,就可以自定义请求数据抓取了。在浏览器中将参数复制下来,构造成一种 json 的格式,即:
postdata = {
'_': 1495027071193,
'bs': "ttyb|个人网站",
'cb': "jQuery110207635110323506591_1495027071143",
'csor': 18,
'json': 1,
'p': 3,
'pbs': "ttyb|个人网站",
'pwd': "ttyb|个人网站",
'req': 2,
'sid': "1432_21085_17001_20927",
'sugmode': 2,
'wd': "ttyb|个人网站"
}
观察看以看到,字段 '_': 1495027071193 代表的是毫秒级的时间戳,这个字段可以在 python 中生成。在 python 中可以用库 import time 来生成时间戳:
import time
nowtime = int(time.time())
但是生成的这个时间戳只是秒级的,及只有 10 位数,而请求数据里面的时间戳是毫秒级别的,有 13 位数,所以这里需要做一个小小的处理。作者这里是生成一个 3 位数的随机数,将其和时间戳拼接起来:
import time
import random
timerandom = random.randint(100, 999)
nowtime = int(time.time())
nowtime + timerandom
时间戳搞定,再看 postdata 里面出现了很多次搜索关键字 ttyb|个人网站 ,所以这里可以都换成一个变量 keyword ,这样就能随时的变换搜索的关键词了。
一切准备就绪后,就可以构造抓取函数了。前文提到 requests 库是非常好用的库,在构造 postdata 的时候可以直接传入而不需要转义成 url编码 ,主体请求函数为:
html_bytes = requests.get(url, headers=header, params=postdata)
url 为前文提到的结构 https://www.baidu.com/s?,header 为请求的头部,如果忘记了请看 4.增加头部,postdata 就是前面构造的 postdata。
def gethtml(url, postdata):
header = {}
# 解析网页
html_bytes = requests.get(url, headers=header, params=postdata)
return html_bytes.content
在代码中调用:
html_bytes = gethtml(url, postdata)
html = html_bytes.decode("utf-8", "ignore")
print(html)
这里可以发现在编码转化的过程中增加了 ignore,这个是为了预防网页中的编码不一致,因为代码中是想将抓取下来的网页的编码转换为 UTF8 的格式,但是有些网页是多格式混合的,例如还会包含 GBK、GB2312 等等,如果混合了多种编码格式的网页,在使用 decode("UTF-8") 的时候会报错,而计入了 ignore 后,酒会自动忽略掉其他的编码格式,只是将 UTF-8 格式进行转换。
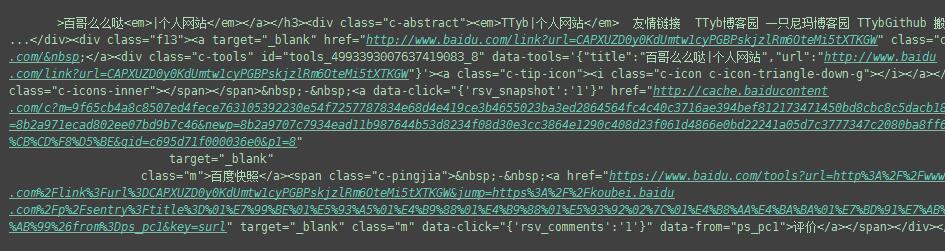
最后,查看一下抓取的效果:
而且 python 中可以接受输入。这里可以将 keyword 用输入的方式写入:
keyword = input("请输入你要搜索的关键词:")
这样抓取的方式更加灵活多变,是不是很好?!
练习
增加百度翻页的效果,即可以选择抓取第2页、第3页等等
源码