目录
初识爬虫
分类: crawlerTTyb 2017-05-09 209
开始教程之前需要安装 Python ,本人所用的 Python 的版本是 Python3.4.4 ,直达下载链接:
Python 又是一个强制缩进的语言,所以一款好的 IDE 是必不可少的,直达下载链接:
安装的教程可以看下博客:
完事具备后,打开 IDE :
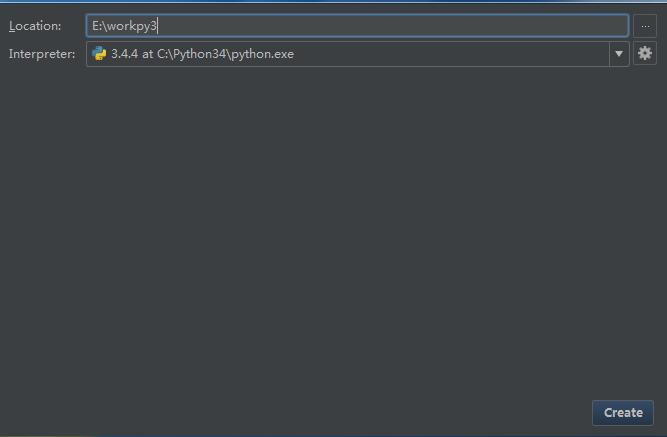
1. Create New Project

2. 设置工程目录 -> Create
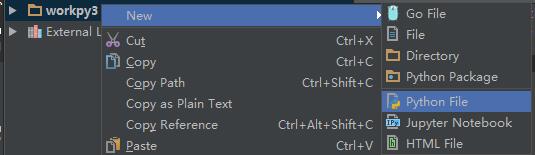
3. 右键 Python File
4.简单爬虫
导入爬虫库:
import urllib.request
设置需要爬取的网页 url :
url = "http://www.tybai.com"
获取全部网页并打印出来:
html_bytes = urllib.request.urlopen(url).read()
print(html_bytes)
得到的结果:
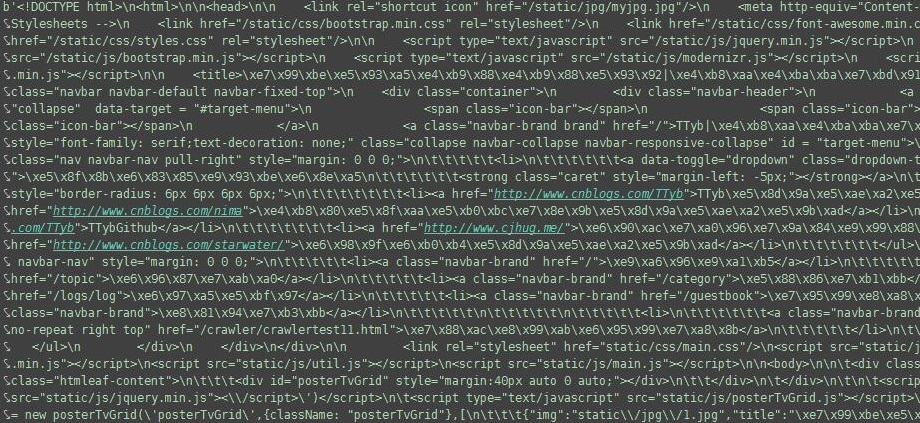
现在得到的结果还是 byte 形式,将其转化为 UTF-8 的形式:
html = html_bytes.decode("UTF-8")
就这样,一个很简单的爬虫就那么实现了!
练习
如何抓取百度首页并将其正确编码打印出来
源码

本文地址:http://www.tybai.com/crawler/1_%E5%88%9D%E8%AF%86%E7%88%AC%E8%99%AB.html,来源于[TTyb],欢迎转载,转载请注明出处。