目录
抓取图片
分类: crawlerTTyb 2017-05-12 738
上文读者应该已经学会怎么提取自己想要的文本信息出来了,那么如何抓取自己需要的图片呢?
例如抓取首页的轮播图 http://www.tybai.com/ :
- 打开谷歌浏览器按
F12,点击箭头- 箭头选中某一张图片,点击
- 鼠标箭头悬浮在
jpg的地方
按照上面步骤可以得到如下图形:
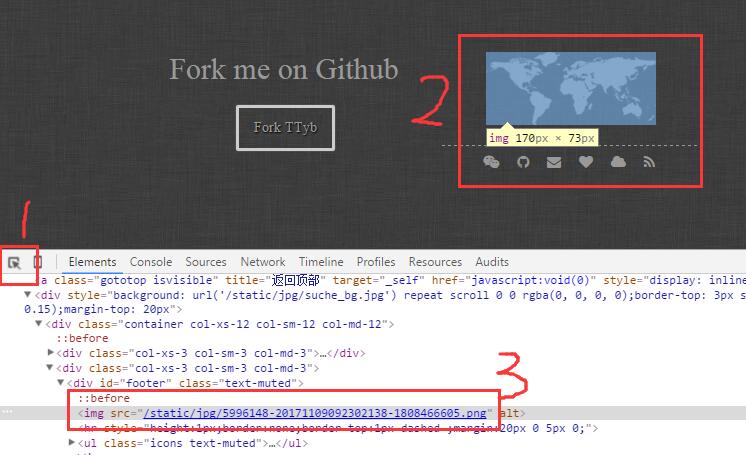
这样可以看到红色箭头指向的图片的 url 为 http://www.tybai.com/static/jpg/5996148-20171109092302138-1808466605.png
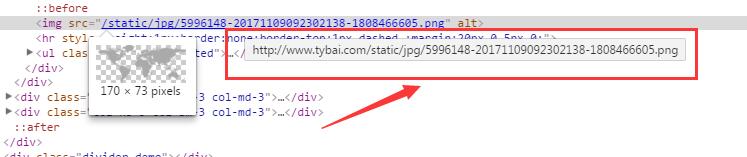
在浏览器地址栏里面输入这个网址:
这样就对了!那么我们看一下 html 里面是怎么写的,按照 第一章 的方法得到图片所在的 html 为:
<img src="/static/jpg/5996148-20171109092302138-1808466605.png" alt="">
很明显这 img 的 url 少了字段 http://www.tybai.com/ 这里可以将其 url 拼接起来,这里我们先将 img 的 url 抓取下来,正则表达式的写法:
# 正则表达式
def reg(html):
reg = r'(<img src=")(.+?)(" alt="")'
all = re.compile(reg)
alllist = re.findall(all, html)
return alllist
返回的样式为:
[('<img src="', '/static/jpg/head.jpg', '" alt=""/>'), ('<img src="', '/static/jpg/wangdachui.gif', '" alt=""/>'), ('<img src="', '/static/jpg/5996148-20171109092302138-1808466605.png', '" alt=""/>')]
这里写个 for 就可以得到里面的 imgurl :
imgurls = reg(html)
print(imgurls)
for imgurl in imgurls:
print(imgurl[1])
得到 img 的 url :
/static/jpg/head.jpg
/static/jpg/wangdachui.gif
/static/jpg/5996148-20171109092302138-1808466605.png
将其拼接起来:
"http://www.tybai.com" + imgurl[1]
最终终于得到我们想要的图片 url 啦,那么就是下载下来就好,下载其实和获取网页 html 差不多的写法:
urllib.request.urlopen(imgurl).read()
主要是要保存在本地,这里是保存到 E 盘,那么如下写法:
saveimg = open("E:/" + str(imgname) + ".jpg", 'wb')
saveimg.write(urllib.request.urlopen(imgurl).read())
saveimg.close()
打开 E 盘,以 wb 的方式保存名字为 imgname.jpg 的图片,为了防止图片重名,这里以加一的方式命名:
imgname = 1
imgname += 1
即图片的名字为依次为 : 1.jpg , 2.jpg , … ,代码为:
# 图片名字
imgname = 1
for imgurl in imgurls:
saveimg = open("E:/" + str(imgname) + ".jpg", 'wb')
newimgurl = "http://www.tybai.com" + imgurl[1]
print(newimgurl)
saveimg.write(urllib.request.urlopen(newimgurl).read())
imgname += 1
saveimg.close()
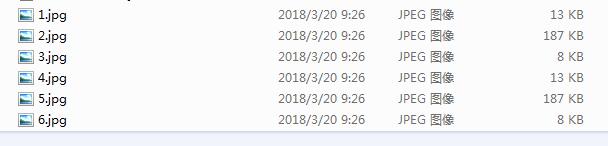
完美下载:
在后面作者抓取的时候发现了一个新的下载的函数 urlretrieve ,自带多线程下载,代码如下:
# 使用urlretrieve下载图片
def cbk(a, b, c):
'''回调函数
@a:已经下载的数据块
@b:数据块的大小
@c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100:
per = 100
print('%.2f%%' % per)
for imgurl in imgurls:
work_path = "E:/" + str(imgname) + ".jpg"
saveimg = open("E:/" + str(imgname) + ".jpg", 'wb')
newimgurl = "http://www.tybai.com" + imgurl[1]
urllib.request.urlretrieve(newimgurl, work_path, cbk)
imgname += 1
完美下载:

练习
用 BeautifulSoup 和 lxml 两种方法抓取首页 百哥么么哒 头像

源码

本文地址:http://www.tybai.com/crawler/3_%E6%8A%93%E5%8F%96%E5%9B%BE%E7%89%87.html,来源于[TTyb],欢迎转载,转载请注明出处。