目录
信息提取
分类: crawlerTTyb 2017-05-11 994
上文已经将网页的信息转码成 UTF_8 并抓取下来了,但是很多信息不是自己需要的,那么怎么提取出自己需要的信息呢?本文提供三种方法:Regex , BeautifulSoup , Lxml.
Regex
按照上文的结果,如果我需要抓取自己网页中的这一句话:

这一句话出现的前后语句为:
<div style="margin:20px">
<marquee direction="left" style="font-family: KaiTi;">不用多久,我就会升职加薪,当上总经理,出任CEO,迎娶白富美,走上人生巅峰|Pretty soon I'll General Manager,be promoted as CEO and marry Bai Fu Mei on the salary increase when pinnacle toward life </marquee>
</div>
根据正则表达式表格:
提取这一句的正则表达式为:
(<marquee)(.+?)(>)(.+?)(</marquee>)
只要取出第三部分的 (.+?) 就可以了,因此代入 python 函数中提取:
import re
def reg(html):
reg = r'(<marquee)(.+?)(>)(.+?)(</marquee>)'
all = re.compile(reg)
alllist = re.findall(all, html)
return alllist[0][3]
回顾上一文抓取首页的代码,得到的 html 是这样子的:
import urllib.request
url = "http://www.tybai.com"
html_bytes = urllib.request.urlopen(url).read()
print(html_bytes.decode("UTF-8"))
将其结果 html_bytes.decode("UTF-8") 代入到函数中:
html = html_bytes.decode("UTF-8")
print(reg(html))
这样就返回了帅气的一句话:
不用多久,我就会升职加薪,当上总经理,出任CEO,迎娶白富美,走上人生巅峰 Pretty soon I’ll General Manager,be promoted as CEO and marry Bai Fu Mei on the salary increase when pinnacle toward life
BeautifulSoup
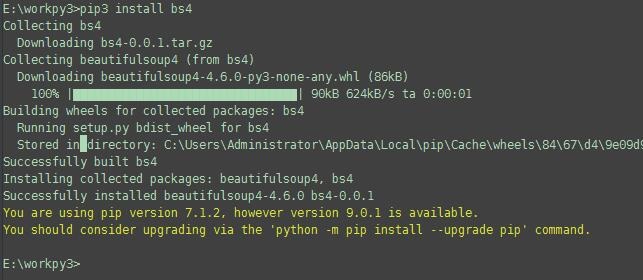
在 python3.4.4 中需要安装这个库,在命令指示符下键入:
pip3 install bs4
如下就算安装成功了:
在代码中初始化网页:
from bs4 import BeautifulSoup
html = html_bytes.decode("UTF-8")
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
提取标签 <marquee></marquee> 中的文本:
info = soup.find('marquee').get_text()
直接得到结果:
不用多久,我就会升职加薪,当上总经理,出任CEO,迎娶白富美,走上人生巅峰 Pretty soon I’ll General Manager,be promoted as CEO and marry Bai Fu Mei on the salary increase when pinnacle toward life
是不是很方便?假设我要提取底部的文本信息 QQ , Github 等:
<ul class="icons">
<li><a href="/contact" class="icon fa-weixin" style="text-decoration: none;"><span class="label">QQ</span></a></li>
<li><a href="https://github.com/TTyb" class="icon fa-github fa-6" style="text-decoration: none;"><span class="label">Github</span></a></li>
<li><a href="mailto:420439007@qq.com" class="icon fa-envelope fa-3" style="text-decoration: none;"><span class="label">420439007@qq.com</span></a></li>
<li><a href="http://www.cnblogs.com/TTyb" class="icon fa-heart fa-3" style="text-decoration: none;"><span class="label">TTyb</span></a></li>
<li><a href="/cloud" class="icon fa-cloud fa-3" style="text-decoration: none;"><span class="label">云世界</span></a></li>
<li><a href="/feed.xml" class="icon fa-rss fa-3" style="text-decoration: none;"><span class="label">RSS</span></a></li>
</ul>
这时候可以先定位到 class="label" ,再提取出里面的信息
infos = soup.find_all("span", attrs={"class": "label"})
for info in infos:
print(info.get_text())
得到结果:
QQ
Github
420439007@qq.com
TTyb
云世界
RSS
Lxml
在 python3.4.4 中需要安装这个库,下载地址为:
本机是 64 位 python3.4 ,所以选择下载 lxml-3.4.2.win-amd64-py3.4.exe ,下载完成后双击安装即可。
在代码中初始化网页:
from lxml import etree
# 初始化网页
page = etree.HTML(html.lower())
抓取 <marquee></marquee> 中的文本代码为:
text = page.xpath('//marquee/text()')
得到的 text 为一个数组,打印出来就是:
["不用多久,我就会升职加薪,当上总经理,出任ceo,迎娶白富美,走上人生巅峰|pretty soon i'll general manager,be promoted as ceo and marry bai fu mei on the salary increase when pinnacle toward life "]
抓取底部信息,则需要定位到 span 且 span 的 class 为 label ,其代码为:
text = page.xpath('//span[@class="label"]/text()')
或者可以写成:
text = page.xpath('//div[@id="footer"]/ul/li/a/span/text()')
又或者可以偷懒,用网页生成的 xpath :
- 首先打开网页 http://www.tybai.com/
F12或者右键查看源码- 找到需要抓取的那一行,右键选择
copy xpath
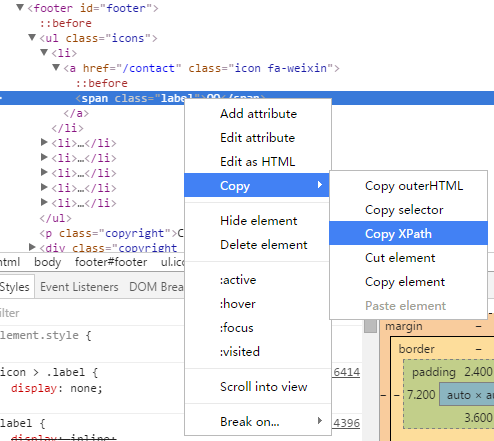
这时候将会得到如下东西:
//*[@id="footer"]/ul/li[1]/a/span
将这一段改写一下:
//*[@id="footer"]/ul/li[1]/a/span/text()
就可以得到结果:
['qq']
练习
用三种方法抓取 [http://www.tybai.com/category](http://www.tybai.com/category) 中的所有文章的标题 ,看一下哪一种方法快且精准
源码

本文地址:http://www.tybai.com/crawler/2_%E4%BF%A1%E6%81%AF%E6%8F%90%E5%8F%96.html,来源于[TTyb],欢迎转载,转载请注明出处。