目录
增加头部
分类: crawlerTTyb 2017-05-13 413
上文读者应该已经学会怎么抓取自己需要的图片了,但是笔者在抓取 http://search.smzdm.com/?c=home&s=rimowa 图片的时候出现如下错误:
urllib.error.HTTPError: HTTP Error 403: Forbidden
403 禁止访问???如果遇到这种错误,那么就是因为遇到了 反爬虫 !!这是反爬虫中比较简单的,由于我们用 python 去访问网页,没有携带任何信息,所以网页很容易判断这是一个程序而非浏览器!
正常一个浏览器访问 url 会携带大量的头部信息:
Accept
Accept-Encoding
Accept-Language
Connection
Cookie
Host
Referer
User-Agent
打开浏览器 F12 ,选择 Network ,选择网址 www.baidu.com ,点击 header 可以看到如下内容:
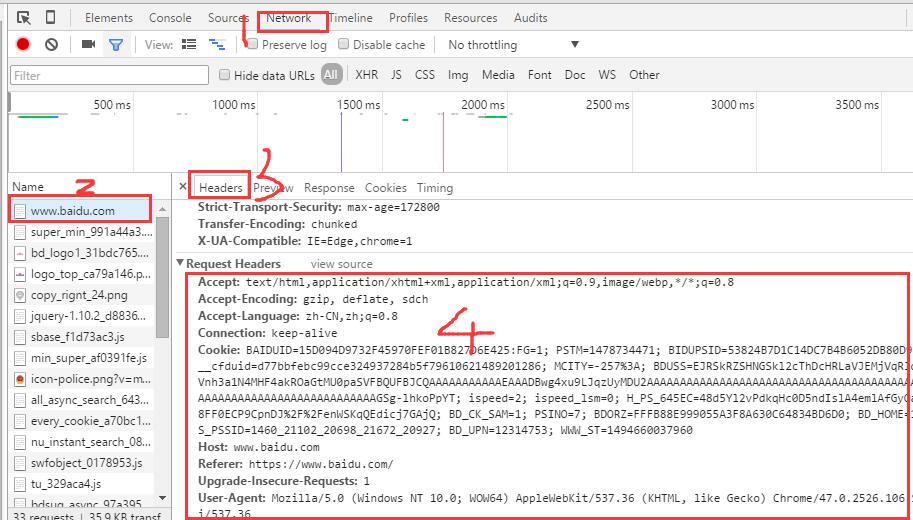
既然被识别出是一个程序,那么我就伪装成一个浏览器访问 http://search.smzdm.com/?c=home&s=rimowa ,首先用真实的浏览器进入这个网页,在网页源码中看到头部信息为:
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:max-age=0
Connection:keep-alive
Cookie:__ckguid=ioY45ASO4Lnu4aaowvV9pU; smzdm_user_view=689CD1C24A23A6BFF477C30153AF04D8; smzdm_user_source=3BD63B497FD4F567BF6C0BEB95A427BF; __gads=ID=a2d28729a6c8c783:T=1493606821:S=ALNI_MYzEzdA7_Tu9d73O1n3LSYiezvo8Q; __jsluid=99afb2ef32391cc0747a0064aafe8c5e; Hm_lvt_9b7ac3d38f30fe89ff0b8a0546904e58=1493606823,1494658634; Hm_lpvt_9b7ac3d38f30fe89ff0b8a0546904e58=1494658634; _ga=GA1.2.2115034789.1493606826; _gid=GA1.2.699948390.1494658638; PHPSESSID=oopol4eegad101c0j5c5c4cdl5; amvid=09e8171e2ae9778f3ad0df7f3c6a86fe
Host:search.smzdm.com
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36
那么伪装这个头部:
# 新建头部
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36'),('Referer','http://search.smzdm.com/?c=home&s=rimowa'),('Host', 'search.smzdm.com')]
加载这个头部:
# 加载头部
urllib.request.install_opener(opener)
然后访问:
html_bytes = urllib.request.urlopen(url).read()
成功得到网页信息!!可以看出只要增加了头部网页就不能直接判断我是否是一个程序了,但是这个方法加载头部比较麻烦,下面推荐另一个封装好的库 requests ,这个库需要安装,在命令指示符下 pip3 install requests ,requests 库设置头部的方法就方便了一下,不需要新建和加载,首先设置头部为:
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Referer': 'http://search.smzdm.com/?c=home&s=rimowa',
'Host': 'search.smzdm.com'}
直接访问:
html_bytes = requests.get(url=url, headers=header)
html = html_bytes.content.decode("UTF-8")
成功!!!这个库封装后简单了很多,完全继承 python 代码量少的风格,随便 10 行不到的代码就能抓取网页下来,作者也是一直对这个库情有独钟,大爱!
练习
用 requests 抓取网页 http://blog.csdn.net/eric_sunah/article/details/11099295 里面的作者头像
源码

本文地址:http://www.tybai.com/crawler/4_%E5%A2%9E%E5%8A%A0%E5%A4%B4%E9%83%A8.html,来源于[TTyb],欢迎转载,转载请注明出处。