目录
异步加载
分类: crawlerTTyb 2017-06-10 1414
上文有提到 异步加载 的情况,所以本文要来抓取异步加载的网页,首选的是百度图片。大家都知道,百度图片是下拉的时候才加载后面的图片,在不使用 selenium 的情况下如何构造 url ?首先用 firefox 打开百度图片, F12 ,输入关键词 图片 ,拉下拉框,当第一次加载图片的时候停止下拉,看以看到出现了一个带有 action 的 url :
http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=图片&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=图片&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=10000000000001e&1496668633422=
这个 url 里面包含的 参数 信息为:
"1496668633422":"",
"adpicid":"",
"cl":"2",
"ct":"201326592",
"face":"0",
"fp":"result",
"fr":"",
"gsm":"10000000000001e",
"height":"",
"ic":"0",
"ie":"utf-8",
"ipn":"rj",
"is":"",
"istype":"2",
"lm":"-1",
"nc":"1",
"oe":"utf-8",
"pn":"30",
"qc":"",
"queryWord":"图片",
"rn":"30",
"s":"",
"se":"",
"st":"-1",
"tab":"",
"tn":"resultjson_com",
"width":"",
"word":"图片",
"z":""
继续下拉,直到下一次加载的时候停止,得到 action 的参数为:
"1496668734273":"",
"adpicid":"",
"cl":"2",
"ct":"201326592",
"face":"0",
"fp":"result",
"fr":"",
"gsm":"5a",
"height":"",
"ic":"0",
"ie":"utf-8",
"ipn":"rj",
"is":"",
"istype":"2",
"lm":"-1",
"nc":"1",
"oe":"utf-8",
"pn":"90",
"qc":"",
"queryWord":"图片",
"rn":"30",
"s":"",
"se":"",
"st":"-1",
"tab":"",
"tn":"resultjson_com",
"width":"",
"word":"图片",
"z":""
发现变化的参数为 1496668734273 、 gsm 和 pn ,按照惯例可以知道, 1496668734273 为时间戳, pn 为页码,每一页的间隔为60,而 gsm 不知道是什么了。在 F12 的脚本中搜索 gsm ,并没有发现 gsm 的生成方式,那么这个 gsm 先不管,先用一个固定的值代替。这样就只需要构造一个时间戳和关键词即可:
import time
import random
def get_tt():
timerandom = random.randint(100, 999)
nowtime = int(time.time())
tt = str(nowtime) + str(timerandom)
return tt
nowtime = get_tt()
keyword = "图片"
pn=30
构造 post 和 headers 去请求:
session = requests.session()
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Referer':
'http://image.baidu.com',
'Host': 'image.baidu.com',
'Accept': 'text/plain, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection': 'keep-alive'}
def getdata(nowtime,keyword,pn):
postdata = {
nowtime: "",
"adpicid": "",
"cl": "2",
"ct": "201326592",
"face": "0",
"fp": "result",
"fr": "",
"gsm": "5a",
"height": "",
"ic": "0",
"ie": "utf-8",
"ipn": "rj",
"is": "",
"istype": "2",
"lm": "-1",
"nc": "1",
"oe": "utf-8",
"pn": pn,
"qc": "",
"queryWord": keyword,
"rn": "30",
"s": "",
"se": "",
"st": "-1",
"tab": "",
"tn": "resultjson_com",
"width": "",
"word": keyword,
"z": ""
}
html_bytes = session.get(url="http://image.baidu.com/search/acjson?", params=postdata, headers=headers)
jsondata = html_bytes.content.decode('utf-8', 'ignore')
jsoninfo = json.loads(jsondata)
return jsoninfo
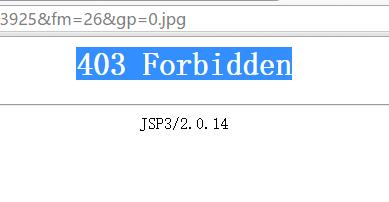
请求后返回了一段 json ,感觉 thumbURL 会是图片的 url ,但是将其复制到网页打开,居然是 403 Forbidden :
最后发现,在百度图片中找到的图片的链接和 thumbURL 的图片链接差了一点:
百度图片:https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=1484342823,356366591&fm=23&gp=0.jpg
thumbURL:http://img5.imgtn.bdimg.com/it/u=2167672004,1418153925&fm=26&gp=0.jpg
只要将 /it/ 前的元素替换掉即可,这里写个正则即可:
import re
def makeurl(thumbURL):
urlhead = "https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy"
reg = r'(.com)(.+)'
all = re.compile(reg)
alllist = re.findall(all, thumbURL)
newurl = urlhead + alllist[0][1]
return newurl
正确的返回了图片的 url ,那么就将所有图片的 url 抓取下来:
def geturl(nowtime,keyword,pn):
jsoninfo = getdata(nowtime,keyword,pn)
urlarr = []
for item in jsoninfo["data"]:
try:
thumbURL = item["thumbURL"]
imgurl = makeurl(thumbURL)
urlarr.append(imgurl)
except Exception as error:
print(error)
threadingrun(urlarr)
此时应该写个多线程同步抓取:
def downloadimg(imgurl, imgname):
header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
"Connection": "keep-alive",
"Host": "ss2.bdstatic.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0"
}
saveimg = open("E:/" + str(imgname) + ".jpg", 'wb')
saveimg.write(requests.get(url=imgurl, headers=header).content)
saveimg.close()
def threadingrun(array):
imgname = 1
# 创建线程池
threadpool = []
# 定义线程
for imgurl in array:
imgname += 1 + int(time.time())
th = threading.Thread(target=downloadimg, args=(imgurl, imgname))
threadpool.append(th)
# 开始线程
for th in threadpool:
th.start()
# 等待所有线程运行完毕
for th in threadpool:
th.join()
最后在 main 函数中写个循环翻页即可:
if __name__ == '__main__':
nowtime = get_tt()
keyword = "图片"
pn = 30
while True:
geturl(nowtime, keyword, pn)
pn += 60
input("暂停")
源码

本文地址:http://www.tybai.com/crawler/10_%E5%BC%82%E6%AD%A5%E5%8A%A0%E8%BD%BD.html,来源于[TTyb],欢迎转载,转载请注明出处。